Releases: MooreThreads/SimuMax
v1.2
SimuMax v1.2 Release Notes
Release status: released
Release date: 2026-05-11
Summary
SimuMax v1.2 refreshes the public B200 benchmark surface, adds formal dense CP
A2A result coverage for B200, improves first-user system-config generation, and
keeps sync-VPP available as Preview.
Supported
- B200 perf-vs-real benchmark summary and reproduction workflow:
- Dense Llama3 B200 CP A2A rows for 32K and 128K sequence lengths.
- Megatron-LM 0.14 selective recompute modeling with
discard_output
semantics throughmegatron_recompute. - Existing public A100-PCIe benchmark summary:
- Simulator trace export through
simulate(), including trace and optional
memory artifacts as documented in tutorial.md.
Preview
- sync-VPP is included as Preview while target-machine validation and support
boundaries continue to tighten.
Representative B200 sync-VPP preview check:
| case | real ms | perf ms | simulator trace end | status |
|---|---|---|---|---|
llama3_70b_l8_tp1_pp4_vp2_dp2_mbc8_sync |
680.70 | 661.21 | 663.29 | Preview |
This row is included only as a current behavior check for sync-VPP. It is not
part of the formal B200 benchmark table.
Tooling
- The public one-click compute-efficiency path supports fresh cache namespaces
through--compute-cache-mode rebuildand--compute-cache-tag. - Strategy configs can opt into Megatron-LM 0.14 selective recompute with
megatron_recompute=trueand a non-emptymegatron_recompute_moduleslist. - GEMM and grouped-GEMM efficiency scripts are aligned with the current
TransformerEngine workspace interfaces. - The shared system-config generation path now verifies that generated configs
can be loaded bySystemConfig.init_from_config_file.
Results
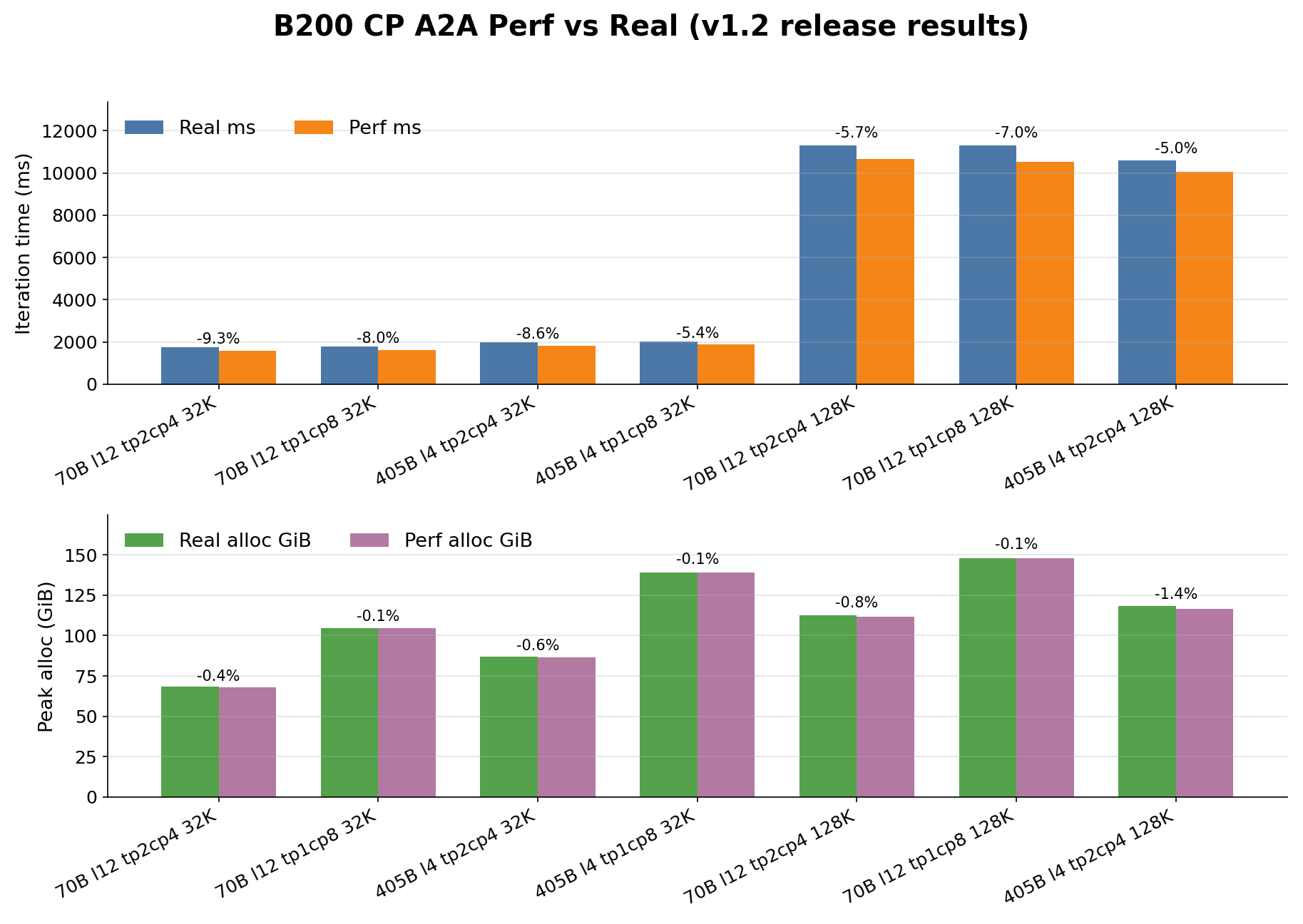
The retained B200 CP rows are dense Llama3 A2A cases. DeepSeek CP rows remain
outside the formal public table.
Known Boundaries
- sync-VPP is Preview, not a broad VPP support claim.
- async-VPP perf timing is not part of the public support surface.
- New or materially different machines should measure their own operator
efficiency and communication data before treating timing estimates as
benchmark-grade.
v1.1
This release expands SimuMax from a pure estimator into a more complete, workflow-friendly platform. It introduces a new end-user application, adds strategy search capabilities, and provides a new system-config generation pipeline with compute/communication efficiency modeling. In addition, it improves compatibility with Megatron-LM 0.14 (notably for MoE) and enhances communication modeling for hybrid parallel setups.
Highlights
-
NEW! SimuMax App (User Application):
- Added a user-facing application to SimuMax to improve usability and streamline common workflows.
-
NEW! Strategy Search:
- Introduced strategy search support to help users explore and identify better parallelization and execution strategies automatically.
-
NEW! System Config Pipeline:
- Added a pipeline to generate system configuration files, including computing efficiency and communication efficiency characterization, enabling more realistic system-level modeling.
Compatibility & Modeling Improvements
-
Megatron-LM 0.14 Support (MoE Updates):
-
Added support for Megatron-LM v0.14.
-
Updated MoE communication behavior: router probabilities are transferred via a separate all-to-all, which:
- introduces a small additional communication cost,
- but reduces GPU memory usage.
-
-
Improved Bandwidth Contention Modeling (Hybrid Parallelism):
- For cases using EP/TP + DP simultaneously, added modeling of inter-node bandwidth contention caused by multiple DP groups competing for network bandwidth.
v1.0
This release delivers a significant breakthrough in the accuracy of memory and performance estimation for large models. It also introduces several major features to enhance model compatibility, flexibility, and user experience.
Highlights
- Dramatically Improved Estimation Accuracy:
- Memory Estimation: Expanded test coverage for both Dense and MoE models. Memory estimation error is now consistently controlled within 1%.
- Performance Estimation:
- On NVIDIA A100-PCIE, performance estimation error is consistently below 3%.
New Features & Enhancements
- MLA Support:
- Introduced support for the MLA model architecture
- Enhanced Layer Specification:
- Added granular control for defining first-stage and last-stage layers in pipeline parallelism, allowing for more optimized model partitioning.
- Advanced MoE Customization:
- Support for customizable dense layers in Mixture-of-Experts (MoE) models, providing greater flexibility in model design.
- Megatron Compatibility Layer:
- Launched a simplified model migration pipeline for effortless conversion and analysis of models built with NVIDIA's Megatron framework.
- Optimized Recomputation Strategy:
- Implemented finer-grained selective recompute, enabling more precise control over the memory-for-computation trade-off to optimize for larger model sizes or higher throughput.
- Comprehensive Efficiency Analysis:
- New capability to measure and analyze efficiency and utilization across various tensor shapes and memory layouts.
Bug Fixes
- Fixed an incorrect token numbers calculation when etp > 1.
- Corrected the FLOPs or memory access (e.g., HBM access volume) calculation for several operators.
- Resolved inaccuracies in the estimated communication volume and associated data types.